
The Governance Implications of AI Tokenomics
A Meta support bot that handed over account access, a smarter approach to AI benchmarking, and the case for putting your AI governance committee in charge of AI tokenomics


1. AI Tokenomics: Cost Controls Are a Governance Problem
By: Andrew Gamino-Cheong
Anthropic released Fable 5 this month at double the price of Opus, and the announcement made sure to mention the various cost management options available to admins for the model’s “Mythos” level capabilities. That focus on cost is unsurprising, as a few events in recent weeks have highlighted some of the growing problems many organizations are facing with AI token costs.
Uber supposedly ran through their entire annual IT budget just on AI tokens by May, and even Microsoft has started to restrict access to some AI tools as a cost control measure. Microsoft CEO Satya Nadella was recently quoted saying that for some tasks the AI token costs can exceed the equivalent human costs, calling into question some assumptions about potential AI impact on the workforce. For the first few years of the GenAI era, most AI systems were heavily subsidized and offered flat-fee subscriptions, but those seem to be fading as most new features of AI platforms are ‘pay as you go’ based on input tokens consumed and output tokens generated. In response, many companies are trying to quickly implement a variety of cost controlling measures, from mandating smaller models, to implementing router type systems, to simply setting hard usage limits per employee per month. The industry has started calling this “AI Tokenomics“ and most of these measures carry governance implications worth analyzing.

Smaller Models: The cost of Claude Haiku is 1/10th the cost of Fable 5, which will make it attractive to use on a number of tasks, however smaller models generally hallucinate more, support much shorter context windows, and have more brittle guardrails. These all increase various risks, creating a key tradeoff between the model size used and the potential harm of the system. As AI costs come under pressure, there will be a key question about risk tolerance ‘per dollar’ that many governance teams may need to get involved with.
Model Routers: Many AI systems have an ‘auto’ selection mode, or have implemented various types of ‘router’ systems that use (ironically) an LLM to analyze a prompt and decide which model to use. The criteria for this decision is often not transparent, and the AI provider has various financial incentives that could impact how they route it, either to save them costs or gain them revenue. If a router selects a smaller model, and that causes the task to fail and create downstream problems, who is liable for that? If model routing becomes more common, or even mandatory, governance teams may need to spend more time analyzing what would happen if a ‘sub par’ model was selected.
Hard Usage Limits: Some companies have started to give each user a hard token or spend limit per month. On the one hand, this distributes responsibility for choosing how to spend tokens to each user, but it also raises other governance issues, including whether allocations track seniority rather than need. Users facing a monthly cap also have an incentive to ration their own tokens, prioritizing their own work and pushing riskier shortcuts onto others.
Key Takeaway: There’s a strong argument that an AI Governance committee and supporting team has the right combination of stakeholders and expertise to set clear standards, policies, and oversight for AI Tokenomics, especially given the potential governance implications of these cost management options.
2. Tech Explainer: Dynamic Benchmark Construction
By: Anastassia Kornilova
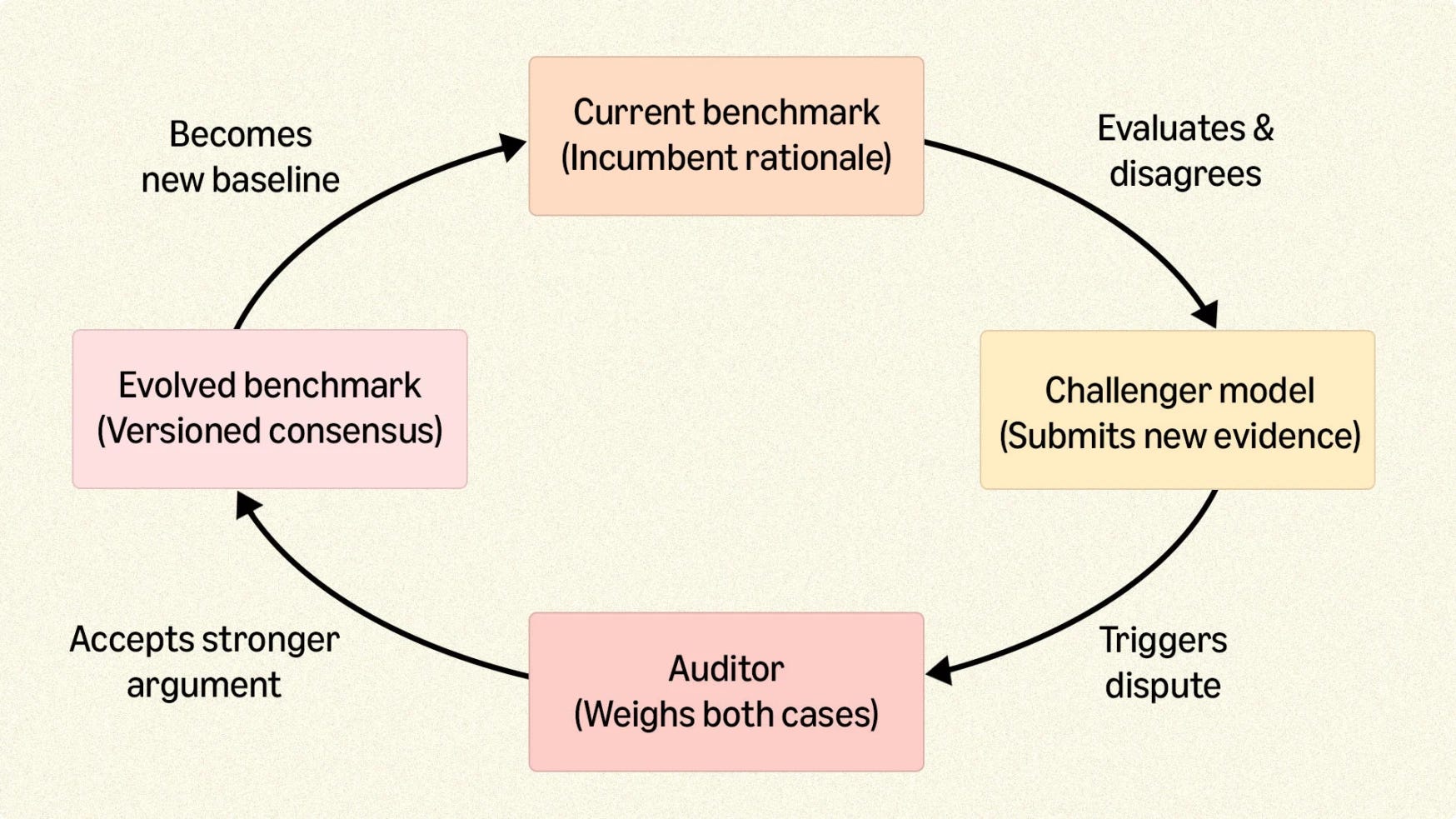
When AI Systems are deployed for complex tasks, constructing a benchmark can become an increasingly complex task on its own. Traditional benchmarks consist of examples with “gold-standard” correct labels that a model’s outputs are verified against.
In a recent study, Amazon recruited PhD-level specialists to verify factual claims in AI-generated research reports and found that they achieved only 60.8% accuracy on claims whose correct answers were already known. This task was difficult because verifying a single claim in a long research report requires reading across multiple documents, synthesizing evidence, and sustaining attention. The researchers propose an alternate “audit-then-score“ approach, where initial benchmark labels are compared against model outputs; when they disagree, the contradictory label and the model’s reasoning are shown to an auditor who can update the benchmark. Across four rounds of audit-then-score, accuracy rose by 30%. Human experts were more adept at comparing two concrete arguments than at starting from scratch. One limitation of this approach is that the audit is triggered exclusively by disagreement: it corrects errors that surface as conflicts, but is blind to cases where the model and the benchmark agree and are both wrong.
Evaluation is an important component of building safe and reliable AI systems. But as models become more capable, traditional “one-shot” human-curated benchmarks are failing to fully capture performance. Beyond the failure mode discussed in this study, traditional evaluations may fail to capture complex behaviors (e.g. is this response safe) and certain error types may not be discovered until the system is deployed. AI-assisted evaluation can help in both cases by using LLM-as-a-Judge scoring and production observability tools. Evaluation should be considered an iterative process where examples are collected and corrected over time. Human involvement in the labeling process remains important, as even advanced models can hallucinate, but the style of review can shift depending on use case.
Key Takeaway: Creating reliable benchmarks for complex tasks is less a one-time exercise than an ongoing process. The audit-then-score approach offers one model for how that can work: using model disagreements to surface labeling errors and shifting human effort toward adjudication rather than cold annotation. For teams building evaluation pipelines for complex AI deployments, the same principle applies: treat your benchmark as a living artifact, document failures as they surface in production, and use human review where judgment is hardest to automate.
3. AI Incident Spotlight: The Support Bot With the Keys to Every Account (AI Incident 1510)
By: Andrew Gamino-Cheong
What Happened: Hackers reportedly took over a string of high-profile Instagram accounts, including the Obama White House account, the Chief Master Sergeant of the Space Force, and Sephora, by simply asking Meta’s AI support chatbot to do it. According to 404 Media, attackers started a support conversation, told the bot to link a new email address to a target’s username, and supplied a verification code from their own account. The bot triggered the recovery flow and handed over access. Meta had announced in March that it was rolling AI support out across Facebook and Instagram with the ability to reset passwords and perform account recovery, and users who lost accounts reported no way to escalate to a human. Meta says the issue is resolved.
Why It Matters: Support agents are dangerous precisely because they have to be powerful. A bot that resets passwords and rebinds email addresses needs write access to the account recovery system, and the cheapest way to build that is to give the agent broad administrative permissions across the whole user base rather than per-session, per-user scoping. That design choice turns a single jailbroken conversation into a master key. The unresolved question is whether an AI agent can ever safely hold the standing privileges that customer support requires, or whether the permission model itself, not the model’s guardrails, is the thing that has to change. Prompt filtering treats this as a content problem. It is really an access-control problem.
How to Mitigate: Scope the session, not the agent. When a support conversation starts, the system should bind the agent’s permissions to the specific account being serviced, so it can act inside that user’s context and nowhere else, regardless of what the conversation talks it into. High-impact actions like rebinding a recovery email deserve a tiered model: lower-risk requests can be fully automated, while account-takeover-adjacent changes route to a human or require step-up verification the bot cannot perform on a requester’s behalf. Identity providers already enforce least-privilege and just-in-time access scoping for human admins; the same principles apply to agents, which most deployments have not yet extended to them.
Key Takeaway: The failure here was not a clever jailbreak, it was an agent holding cross-account admin rights it never needed for any single support session. Before deploying a support agent, assume the conversation will eventually be adversarial and ask what it can reach when it is. If the answer is “every account,” the guardrails are in the wrong layer.

4. Trustible Spotlight: AI Chatbot Legislation
By: Lauren Madden
13 US states have enacted legislation governing AI chatbots, and nearly 30 more have proposals in motion.
Our AI Governance and Policy manager reviewed 14 laws across those 13 states and found four themes running through nearly every one: mental health and crisis protocols, minor protections, deception and manipulation prevention, and enforcement. The laws share common ground but diverge on the details, and the sharpest dividing line is private right of action. Seven states let users sue directly; the rest rely on state attorneys general. Federal bills are advancing too, with at least one that would conflict with individual liability provisions states have already enacted.
Here’s where things stand. Read more.
5. Policy Updates
By: Sydney Cullen
The White House EO. After postponing the signing a few weeks ago, President Trump has signed an Executive Order on AI innovation and security. This EO directs defense and national security agencies to upgrade cyber defenses and establishes a voluntary process through which frontier AI model providers can submit their models to government benchmarking prior to deployment to assess potential cybersecurity risks.The only substantive change from the draft EO to this final EO is the pre-release window dropped from 90 days to 30 days, reflecting the pace of innovation. Separately, NSPM-11 lays out a sweeping AI strategy for the national security enterprise organized around four pillars: adoption, adaptation, assurance, and accountability. It directs the Department of Defense to update its autonomy-in-weapons directive, establish a reserve of non-governmental AI talent, and build a joint AI data and model exchange.
Our Take: Together, the EO and NSPM signal that national security is the administration’s preferred lens for governing frontier AI developers, letting them set expectations for risk mitigation and model access without triggering their own anti-regulation talking points.
The Great American AI Act. Representatives Jay Obernolte (R-CA) and Lori Trahan (D-MA) released a 269-page discussion draft of the Great American AI Act (GAAIA), a bipartisan federal AI bill that would establish transparency and audit requirements for frontier model developers, create a federal system of licensed “Independent Verification Organizations” to conduct semi-annual audits, and preempt state laws specifically regulating AI model development for three years. The draft consolidates more than a dozen bipartisan bills on cybersecurity, workforce, and AI research. While the preemption provision would override state developer requirements laws like California’s SB 53, New York’s frontier law, and potentially the Illinois bill described below, it does leave post-deployment state laws intact.
Our Take: If the preemption language sticks, much of the state-by-state compliance burden disappears for model developers, but deployers operating in regulated industries should not expect relief since the preemption provision does not impact post-deployment state laws.
UK CMA conducts Google. The UK’s Competition and Markets Authority (CMA) imposed a conduct requirement on Google search under its digital markets competition regime, requiring publishers to have the ability to opt out of their content being used to power AI features like AI Overviews, and requiring Google to properly attribute publisher content in AI-generated results. The CMA flagged it will monitor Google’s response to these requirements and could create additional requirements they see fit.
Our Take: Most publisher-AI disputes have played out through copyright litigation or voluntary licensing negotiations. The CMA is doing something different, using competition law to force a structural opt-out mechanism into the product itself. If this model spreads to other jurisdictions, the content provenance and attribution questions that AI governance teams have been flagging for years start to have answers that don’t depend on the goodwill of the model provider.
In Case You Missed It:
CHAI. The Coalition for Health AI published eight governance playbooks covering AI policy, risk assessments, lifecycle management, third-party management, and more, developed across 150+ healthcare organizations. For health systems evaluating AI vendors, these playbooks provide a useful framework to use in procurement and contracting conversations now.
Illinois. The Illinois legislature passed SB 315 unanimously, requiring large frontier AI developers to publish a transparency framework covering model capabilities, catastrophic risk assessments, and safety incident response. Notably, Illinois goes further than California and New York by mandating third-party audits.
Singapore. Singapore’s PDPC launched a public consultation on proposed advisory guidelines for using personal data in generative AI systems. The guidelines are non-binding but will inform how PDPA obligations are interpreted in enforcement.
—
As always, we welcome your feedback on content! Have suggestions? Drop us a line at newsletter@trustible.ai.
AI Responsibly,
- Trustible Team