
The Hiring Arms Race Nobody Can Win
Where runtime enforcement belongs in AI governance, why Waymo's AI missed construction zones, and why model dependency is now a concentration risk


1. AI Escalation in Hiring
By: Andrew Gamino-Cheong
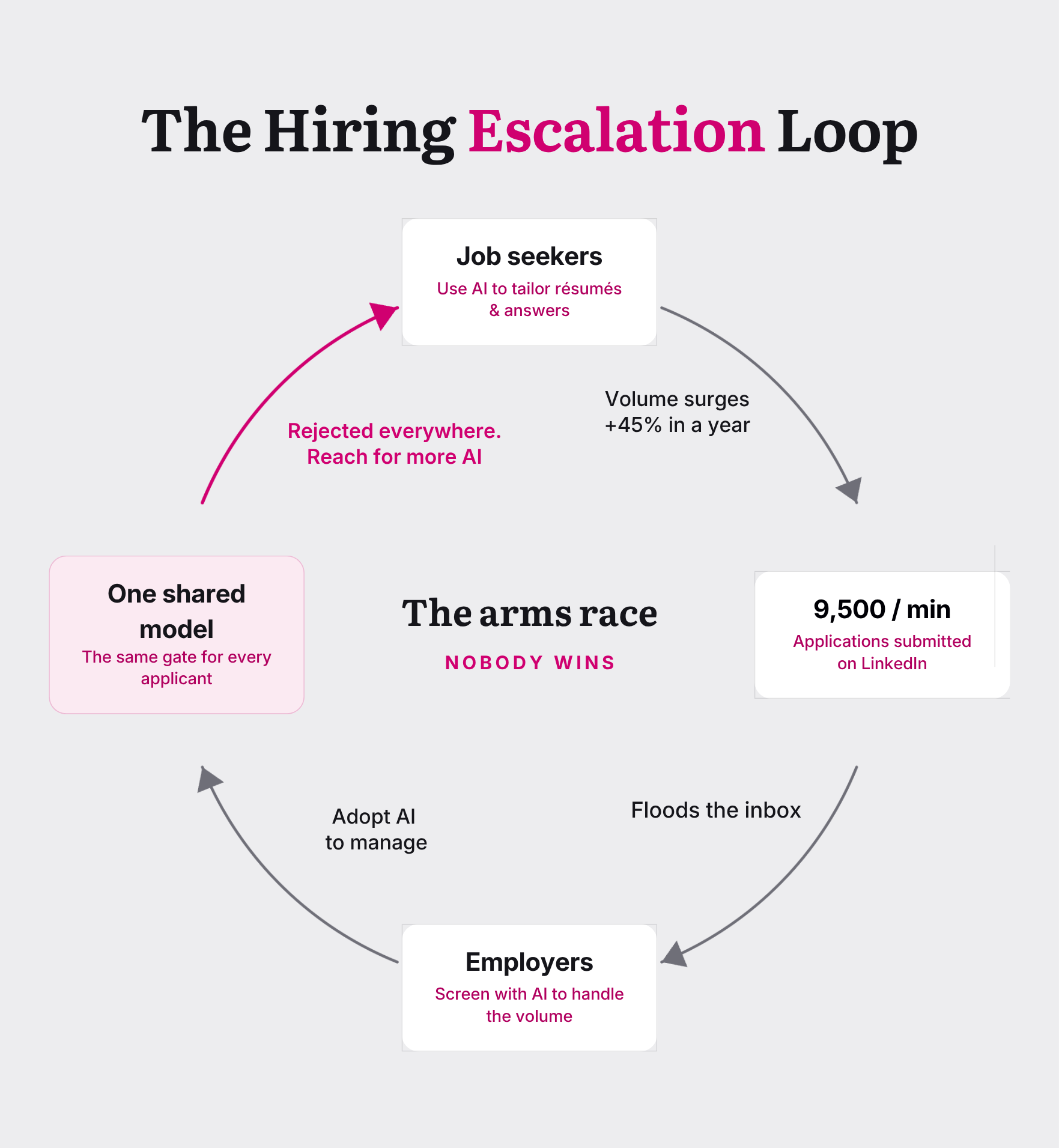
Job seekers and employers are now locked in an escalating loop, each side reaching for AI to outpace the other, and the result is a hiring market that works worse for everyone in it. Candidates use large language models to write and tailor resumes, agentic tools to auto-apply to hundreds of postings at once, and increasingly to slip past the screening questionnaires meant to thin the pile. Roughly 73% of students and graduates now use AI somewhere in the application process, up from 55% a year earlier, per a recent survey. The volume that produces is staggering, with LinkedIn reporting that application submissions jumped more than 45% in a year to nearly 9,500 every minute, and one communications agency reporting more than 2,000 applications for a single graduate role.
Faced with that firehose, employers have little choice but to answer AI with AI. Even the EU is not exempt. According to Euractiv, the European Commission, whose recent generalist competition drew 174,922 applications, nearly three times what was expected, is in final testing on a tool built atop Anthropic’s models to score and rank candidates. The body that wrote the law classifying CV-ranking as high-risk is now adopting exactly that, running on a US model, because manual screening no longer scales. Once the inbox hits six figures, there is almost no other move available.
Choosing Claude is unsurprising given the market perception that their models are less biased, and better ‘aligned’. The main problem could arise if the majority of organizations, or applicant tracking systems all choose to use the same model.
Recent Stanford research surfaces exactly that risk, one that no bias audit is built to catch because it lives across many organizations rather than in any single tool. Analyzing 4 million applications screened by one vendor, the researchers found that when many employers run the same model, rejection stops being independent, with roughly 4% of applicants who applied to ten jobs rejected from all ten, more than chance predicts. Human screeners are plenty biased too, but their biases are inconsistent, and that noise means a candidate rejected by one reviewer has a real shot with the next. A monoculture removes even that accidental mercy. The unsettling part is that this holds even if the shared model is a good one. A screener can be accurate, audited, and demonstrably fair on its own terms, and still produce a societal harm once it becomes the single gate every applicant passes through, because fairness measured one decision at a time says nothing about what happens when the same judgment is applied everywhere at once. The same people get the same “no” from every employer, and there is no longer any other door to try.
Key Takeaway: Most AI governance teams will review a hiring tool in the coming year, so it’s important to build in the right controls now, and understand the potential risks. This includes route candidates through several models rather than one vendor, testing directly for whether the screener favors AI-polished resumes over human-written ones, and keeping real human review at the points where a filter can silently drop a qualified person.
2. Balancing Transparency and Safety in Safeguards
By: Anastassia Kornilova
When Anthropic briefly released Claude Fable last week, two of the safeguards drew immediate scrutiny: a silent fallback to a previous version of the model, Opus 4.8, and intentionally reducing the effectiveness of outputs (sandbagging) for certain frontier AI tasks. The measures targeted three categories of requests: unsafe queries (offensive cyberattacks, biological and chemical weapons), potential knowledge distillation attempts (Anthropic has previously reported that DeepSeek, Moonshot AI, and Minimax have used millions of exchanges to train their own models, and this behavior is prohibited by their terms of service), and frontier LLM development tasks that could accelerate a competitor’s capabilities. The decision to route to a different model silently was made to make it harder for malicious actors to circumvent the protections, since methods like Boundary Point Jailbreaking use automated analysis to find viable jailbreaks.
These safeguards caused intense backlash from the research community, and the two mechanisms create distinct evaluation problems. Silent fallback corrupts the identity of what’s being evaluated, since the outputs don’t represent the model’s true capabilities. This makes it harder to reproduce findings reported in system cards, which is already a challenge given how nuances in prompting and agentic harness setups can significantly impact results. An explicit rejection gives researchers a clearer signal to report on and can help explain differences from internal results. Anthropic does work with third-party auditors and includes those results in system cards, but this approach doesn’t give academic and independent researchers access to the systems. Based on the feedback, Anthropic removed the silent fallback and introduced explicit signals and controls for this behavior.
Key Takeaway: Sandbagging on frontier AI research creates moats around who can do certain types of research. Frontier AI labs face a balancing act between mitigating safety threats and allowing benign safety research, and between protecting their IP and supporting a richer research ecosystem. Possible compromises include broader structured access frameworks that give vetted researchers pre-deployment access under NDA, and transparency about when capability suppression is active and how it affects evaluation, so that downstream users and auditors can properly assess the validity of their findings.
Sandbagging performance and silent fallbacks can be effective mitigations for AI Safety risks, but reduced transparency about these choices can impact trust from stakeholders. Anthropic’s initial decision highlights yet another challenge with creating reproducible evaluations when working with external models.
3. AI Incident Spotlight: When the Map Runs Out (Incident 1547)
By: Andrew Gamino-Cheong

What Happened: Between April and May 2026, thirteen Waymo vehicles drove into active freeway construction zones in Phoenix and the San Francisco Bay Area. The vehicles drove past ramp closure signs into pre-planned construction zones in Phoenix, then drove between lane closure cones in the Bay Area. In response to these, and other issues, Waymo filed a voluntary recall with NHTSA covering 3,871 vehicles. According to the NHTSA recall filing, the system failed by “inappropriately prioritizing the avoidance of other freeway hazards.” The car wasn’t asleep at the wheel. It was looking at the wrong things on the road.
Why It Matters: The AIID record groups 13 related events across six weeks before Waymo issued the recall. That timeline matters as much as the failures themselves, and it surfaces a question the AV industry hasn’t answered: who’s responsible for keeping AI systems current with a physical world that changes faster than any map? Construction zones are temporary by design. A police officer can close a lane in seconds. The ADS didn’t fail because sensors malfunctioned. It failed because reality outpaced its model of reality. A software patch fixes the specific failure mode. It doesn’t fix the physical to data world drift.
How to Mitigate: NIST’s AI RMF treats post-deployment monitoring as a distinct governance function for exactly this reason. For AV operators, the USDOT’s Work Zone Data Exchange (WZDx) standard offers a real-time data integration path that’s available but not consistently adopted. Any operator running AI in a dynamic physical environment needs a defined threshold for when the gap between a system’s world model and the actual world is too wide to keep going, and a clear policy for what happens when that line is crossed.
4. Trustible Spotlight: Where Runtime Enforcement Belongs in AI Governance
By: Lauren Madden
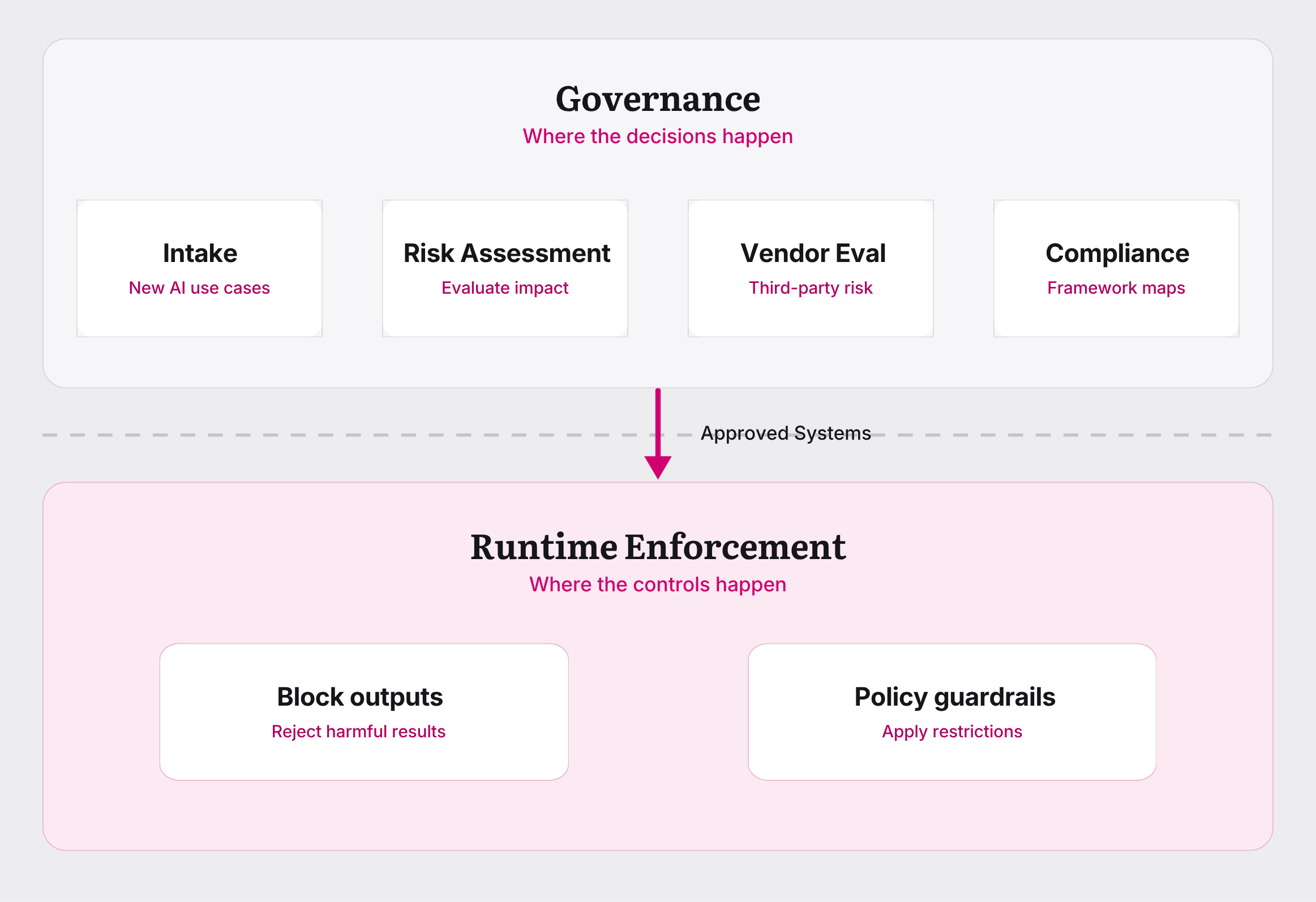
Runtime enforcement (blocking outputs, applying policy guardrails) is critical infrastructure for AI systems. It’s also different from governance itself.
Governance happens upstream: in intake, risk assessment, vendor evaluation, compliance mapping. Runtime enforcement sits at the enforcement layer. Both matter, but neither works alone. Gartner’s latest AI Governance Market Guide explores this distinction across platform categories.
We detail this in our “16 Types of AI Governance Platforms” guide, which breaks down where each control lives in the stack. And for the full design picture on where runtime enforcement actually belongs in your architecture, our “Governance by Design: Where Runtime Enforcement Belongs” post walks through it.
Understanding where governance ends and enforcement begins makes the whole stack clearer. Read more.
5. Policy Updates
By: Sydney Cullen
The Anthropic Ban Reorders Who Controls Frontier AI
After business hours on June 12, the Commerce Department ordered Anthropic to cut off all foreign-national access to its newly released Fable 5 and Mythos 5 models, citing national security concerns. Because the company can’t screen users by nationality in real time, it disabled both models for everyone, worldwide. Anthropic says the trigger was a narrow jailbreak whose capabilities are widely available from other models. The technical dispute matters less than the precedent. Washington has now demonstrated that it will reach into a commercial lab and switch off a deployed product, and that the order will land on allies as hard as on adversaries. Three reactions are worth watching.
Congress. Lawmakers in both parties responded with skepticism rather than support. Several said they hadn’t even been briefed on the reasoning, and a bipartisan group of House members has formally demanded the administration explain why Anthropic was singled out and whether rivals should expect the same. Beyond the immediate objections, members of both parties said they now see an opening to mobilize their colleagues around legislation that would reclaim congressional authority at a time when the executive branch remains firmly in the driver’s seat on AI regulation. Whether that translates into an actual statute is a separate question, but the political incentive to act has shifted.
US Allies. A model marketed three days earlier as Anthropic’s most capable public release became unavailable to European users by a foreign-government’s decision, with no warning or recourse. The EU has growingly been concerned about their dependency on US AI models for this specific reason. Countries that have built services, security functions, and critical infrastructure on top of these models are forced to comply with orders from Washington. And as long as the US keeps its technological lead, that exposure isn’t a one-off.
AI Diplomacy. At the G7 in Évian, the CEOs of the leading American labs were seated as peers of national leaders, holding bilateral meetings and posing with President Macron in a chair usually reserved for a head of government. Macron is pushing for a “trusted partners” scheme that would restore allied access to Fable and Mythos without requiring Washington to drop its broader restrictions. It will be in the US interest to figure out this balance, since no government will continue to buy AI it knows can be switched off without warning. The Anthropic standoff is a preview of a dynamic where governments and a handful of private companies negotiate directly over what is becoming national infrastructure.
Key Takeaway: Frontier model access is now a lever of statecraft, not a routine procurement choice. Governance teams should treat reliance on any single model, foreign or domestic, as a concentration risk, mapping where one provider underpins a critical function and lining up contractual exits and fallbacks before the next directive, not after it.
In Case You Missed It:
First religious exemption from workplace AI. A North Carolina software engineer secured a Title VII religious accommodation letting her opt out of mandatory AI tools at work, reportedly the first of its kind. Although this case began prior to Pope Leo XIV’s remarks on AI, we will likely see the encyclical cited in other religious exemption requests. Whether the encyclical is enough to constitute grounds for an exemption is still up in the air, since Pope Leo XIV does not explicitly direct to not use AI. But a 2023 Supreme Court case made it much harder for employers to deny religious accommodation requests, so that combination may prove effective for workers opposing the use of AI in their jobs
EU. The European Parliament gave final approval to the AI Act simplification package. The deal postpones high-risk obligations to December 2027 for standalone systems and August 2028 for embedded safety components, and narrows the “safety component” definition so AI features that merely assist or optimize don’t automatically inherit high-risk duties. It also creates an outright ban on AI “nudifier” apps that produce non-consensual intimate imagery or CSAM, with a December 2026 compliance deadline. The text still needs formal Council adoption.
Brazil and EU. The two signed an agreement in Brasília on June 12 covering AI, data governance, and digital infrastructure, building on January’s mutual data-adequacy decisions. It’s the EU’s fifth such partnership and another move to build trusted digital cooperation outside the US-China axis.
—
As always, we welcome your feedback on content! Have suggestions? Drop us a line at newsletter@trustible.ai.
AI Responsibly,
- Trustible Team