
What the AI Audit Ecosystem Can Learn From the Delve Scandal
Lessons from a SOC 2 scandal, agent memory risks, and what a mistranslated space mission reveals about AI deployment


1. What the AI Audit Ecosystem Can Learn From the Delve Scandal
The cybersecurity world has spent the past few weeks reeling from a major scandal involving Delve, a YC-backed compliance startup that promised to get companies SOC 2 compliant in days using proprietary AI. SOC 2 is a general cybersecurity standard that most startups need before selling software to enterprises. According to a series of Substack posts, Delve didn’t have much in the way of AI, allegedly stole another company’s IP, and was auto-generating fraudulent SOC 2 reports through offshore firms. Delve has since been disowned by its investors, lost its most notable customers, and sparked an ongoing public debate about the “race to the bottom” in the SOC 2 world.
There’s plenty of AI directly involved in the Delve scandal, but there are also important lessons for the developing AI assurance and audit ecosystem. While many criticize SOC 2 as too light, consisting mostly of check-the-box activities, it can be a useful education for early-stage startups learning which basic security controls to put in place, and it’s often the first stepping stone towards heavier certifications. The real issue is less about the standard itself and more about the incentives surrounding it. The first problem is that SOC 2 lacks a strong auditor certification and enforcement ecosystem. It was created by the AICPA, a trade association of public accountants, originally to set standards for sharing confidential financial data with auditors, and has since been extended to cover SaaS platforms broadly. Unlike ISO, the AICPA does not formally certify and credential its auditors. The second problem sits on the demand side. Many enterprise procurement teams don’t understand how startups work and demand unqualified SOC 2 reports, even though the intent of the standard is to provide transparency about risks that can then be negotiated. Procurement teams will often use “findings” (auditor observations about control gaps) as an excuse to eliminate vendors rather than as a starting point for risk-based discussions. This creates intense market pressure for performative compliance over honest disclosure, and rewards bad actors over those being transparent. Given how quickly AI is evolving, any audit or assessment will have limitations. Businesses that start demanding “perfect” AI audits risk creating the same dangerous incentives, reducing the amount of meaningful risk management done for procured AI systems.
Key Takeaway: The incentives in an assurance ecosystem matter as much as the standards themselves. Right now, most risk information about AI isn’t being disclosed because teams worry that disclosures will be treated as admissions of liability or make their systems less attractive. Policymakers should think hard about how to make the opposite true, where transparent disclosure of risks and audit findings is rewarded, not punished, in the market.
2. Tech Explainer: Understanding Agent Memory
Memory is a core component of AI agents, but the term can refer to several different things. As agents increasingly operate across multiple sessions and workflows, how they store and retrieve information has direct implications for transparency, data rights, and security.
Short-term memory refers to the data passed to a model during a single interaction, typically conversation history, system prompts, and tool outputs. Developers may use summarization to condense previous interactions to fit a model’s context window, which can result in performance degradation if important details are not preserved in the summary.
Long-term memory refers to the use of external databases that track information across multiple interactions with an AI Agent. A simple form might include a database of previous conversations (episodic memory); a more complex form might include a knowledge base that summarizes information across sessions (semantic memory). For semantic memory, new records are often created through agentic processes that analyze previous conversations, meaning the agent is deciding what to remember. The agent interacts with the memories using tools, similarly to interactions with other external resources.
Depending on the nature of the store, it may be difficult to audit and manage the long-term memories. Deleting a specific chat from an episodic store may be straightforward, but summarized semantic knowledge is harder to disentangle. If two conversations contributed to a stored fact and one is deleted, the system may not be able to determine whether the fact should be forgotten.
Agent memories also present a vector for adversarial attacks. If a malicious actor gains access to the long-term memory database, they can plant bad data and execute indirect prompt injections that persist across sessions.
Key Takeaway: While memory can make agents more effective, it introduces new governance challenges. Users of external AI systems need to understand how their “memories” are managed, while developers need to account for the transparency, legal and security risks associated with long-term memory stores.
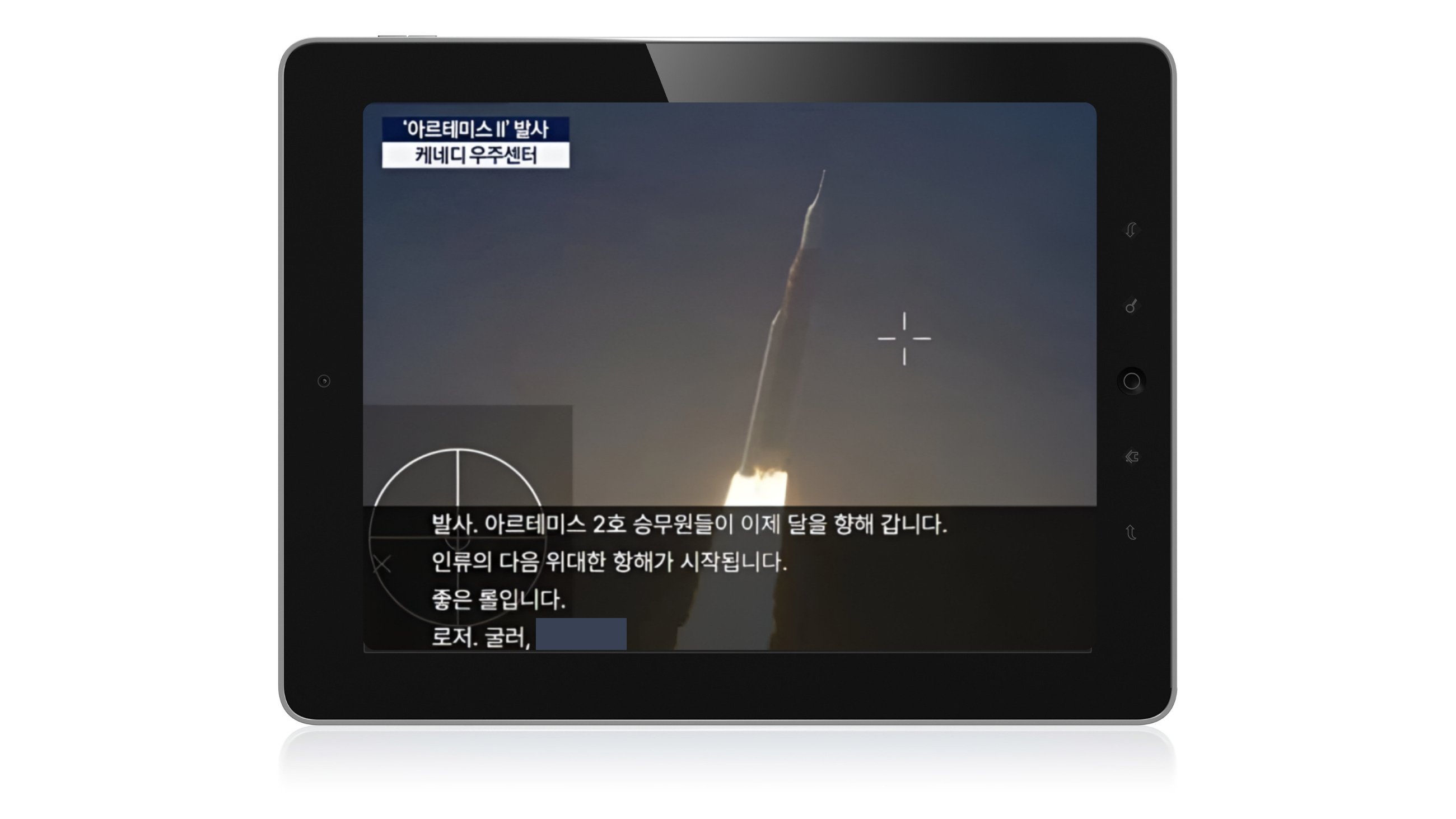
3. Incident Spotlight: When the Model Doesn’t Know What It Doesn’t Know (Incident 1446)
During KBS’s live YouTube broadcast of the Artemis II launch on April 1, the broadcaster’s AI real-time translation system rendered the mission control phrase “Roger, roll, pitch” as “Roger, roll, b*tch” in Korean subtitles. The error spread quickly on social media and KBS issued an apology the same day. The fix was straightforward: disable rewind, remove the clip, and commit to improving profanity filtering. Case closed, apparently.
But that resolution actually obscures the more interesting governance failure here.
Why It Matters: KBS’s response framed this as a profanity filtering problem, and their proposed fix, strengthening the profanity filter, treats it as one. The AI system mistranslated “pitch” as an English expletive, then rendered its Korean equivalent, because it failed to recognize the aerospace context of the communication. The underlying issue isn’t that a bad word slipped through a filter; it’s that the system had no representation of the domain it was operating in. Aviation and mission control communication is highly formalized, uses a specific vocabulary, and is nothing like the natural language corpus these models are typically trained on. Adding profanity filtering is a patch on a context problem. The next domain-specific failure, whether in a medical broadcast, a legal proceeding, or a financial earnings call, will produce a different kind of error that the patched filter won’t catch.
This incident also sits at the edge of a broader unresolved question: who bears accountability when an AI-generated output causes harm during a live, unedited broadcast? KBS worked with an unnamed external partner for the translation system, and its apology references “close consultation with relevant departments and external companies” to prevent recurrence. That language is telling. When the vendor relationship is opaque and the system is live, the contractual and editorial accountability structure is rarely established in advance.
How to Mitigate: The immediate lesson isn’t “add profanity filters”; it’s “don’t deploy general-purpose translation models in specialized domains without domain adaptation or human review gates.” For broadcasters and enterprises running real-time AI outputs in public-facing contexts, the risk controls should mirror those applied to any live content: a human in the loop capable of interrupting the stream, domain-specific fine-tuning or prompt configuration for the subject matter, and a vendor contract that clearly allocates responsibility for output errors. Some broadcasters using AI captioning tools have begun requiring vendor indemnification clauses for live content errors specifically. That’s the right instinct, though the contractual frameworks are still nascent.
Key Takeaway: Profanity filtering is not a substitute for domain-appropriate AI deployment. Any organization running AI-generated outputs in a live or real-time context, in any specialized domain, should establish both a human interrupt capability and clear vendor accountability before go-live, not after the first incident.

4. Trustible AI Governance Market Guide
The AI governance software market is crowded, confusing, and increasingly hard to navigate. Search “AI governance platform” and you’ll find hundreds of products sharing the same label: AI firewalls, privacy compliance tools, model monitoring services, cybersecurity GRC products with a new AI module. They’re all technically accurate descriptions, and they’re all describing fundamentally different products built for different teams solving different problems. That confusion leads to real procurement mistakes, organizations buying the wrong tool, or forcing a point solution into a coordination role it was never designed for.
To help cut through the noise, we put together a market guide that maps 16 distinct categories of platforms claiming some version of “AI governance,” organized by where they sit in the technology stack. For each, we describe what it actually does, who buys it, and where it falls short on the broader governance mandate. Whether you’re building a program from scratch, writing an RFP, or just trying to make sense of a vendor pitch that landed in your inbox, it’s designed to give you a clearer frame for evaluation. Read the full guide here.
5. Policy Round Up
Fannie Mae: Fannie Mae has released their first AI governance framework for the use of AI in mortgage lending. It includes guidelines for policies and procedures that sellers and servicers must abide by if utilizing AI/ML in the selling/servicing of Fannie Mae loans. It emphasizes transparency, risk management, and requires an owner of the AI use case to assume the responsibility of implementing and maintaining this framework.
Our take: This follows in line with guidance released by Freddie Mac, one of the other major players in mortgage lending. While there may not be federal guidance, regulated industries are pushing forward with risk management practices.
OMB Compliance: Deadlines for compliance with high-impact AI risk management practices have recently passed. Several agencies also missed their deadlines for posting updated AI inventories, a crucial step in determining what cases are high-impact. Additionally, a requirement of OMB’s AI Acquisition guidance directs agencies to contribute to a repository of AI acquisition best practices. Monday’s new GAO report found agencies struggled with this due to a lack of centralized documentation and agency-level guidance.
Our take: While the goal of the OMB guidelines is to streamline AI adoption, the requirements can actually be quite a heavy lift for agencies.
CA EO (3/30): Governor Newsom signed a new state Executive Order on the state’s procurement of AI services. It aims to provide a new process for the state’s AI procurement in effort to allow CA to separate from federal government’s processes in light of the Trump Administration’s recent “contracting missteps” (i.e. Anthropic). It gives the state the ability to do its own assessment of the policies and safeguards of AI companies and utilize the tool upon approval, even if this goes against the federal government’s supply chain risk designations.
Our take: The Trump Administration has thus far expressed intent to allow states to have rights over their AI procurement processes, but it is unclear whether a state has the ability to override a national security designation. We can expect there to be more legality questions once the specific guidelines come out around August.
In case you missed it:
China: The Chinese government has released Interim Measures for the Management of Anthropomorphic AI Interaction Service. It covers protections, especially for children, who are interacting with AI services that both 1) possess anthropomorphic features and 2) provide emotional interaction. It is a novel step forward in the already pretty rich well-developed Chinese AI regulatory landscape.
xAI sues Colorado: xAI is suing the state of Colorado over their anti-discrimination AI law, set to begin enforcement in June. xAI argues that this would be a first amendment, free speech violation and would force them to “embed the State’s preferred views” into their systems.
—
As always, we welcome your feedback on content! Have suggestions? Drop us a line at newsletter@trustible.ai.
AI Responsibly,
- Trustible Team